웹페이지 돌아다니다가 글 쓰려고 하면 스팸 방지 등을 위해서 그림으로 문자들을 보여주고 문자를 사용자가 입력하여 확인하는 경우가 있습니다.
최근에 제가 rapidshare.com와 badongo.com에서 자료(?)를 받는데 일반 사용자는 다운로드 받을때 그림을 보고 입력하는 부분이 있습니다. 프로그램으로 기계적으로 다운로드해서 네트워크 부하를 많이 일으키지 못하도록 하는거죠. 이미지는 아래와 같이 생겼고, rapidshare에서 사용하는 이미지는 글자의 왜곡이 거의 없네요.
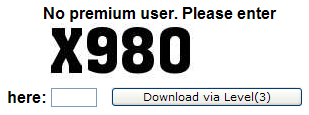
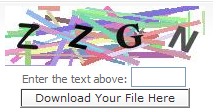
프로그램적으로 저런 이미지를 읽기가 얼마나 어려운지 모르겠지만, 간단히 이미지에서 글을 읽기 힘들기 때문에 조금더 어렵게 하는 의미는 있겠죠.
위와 같은 기술을 CAPTCHA라고 하는데, 위키피디아에서 많은 정보를 얻을수 있습니다. CAPTCHA는 Completely Automated Public Turing Test to tell Computers and Humans Apart의 약자라고 하는데, 컴퓨터와 사람을 구별하는 완전히 자동화된 테스트 정도 되겠네요. 약자를 그럴듯하게 만들기 위해서 약간 부가적인 단어가 들어간듯 싶습니다. CMU에서 만든 용어고 CMU에서 많이 연구를 했나봅니다.
이미지를 복잡하게 만들면 문자를 읽어내는 프로그램을 만들기가 더 힘들지만, 사람 역시 문자를 판독하기가 어려워진다고 합니다. 일반적인 홈페이지에서는 CAPTCHA를 도입하는 것만으로도 악의적인 사용자의 공격을 어렵게 만들수 있지만, 사이트를 공격할만한 가치가 크다면 문자를 판독하는 알고리즘을 개발할수도 있고, relay 공격으로 CAPTCHA 문제들을 자동화해서 풀수도 있습니다. relay 방법은 알고리즘을 통해서 문자를 읽는것이 아니라, 사용자가 어느정도 있는 사이트를 악의적인 사용자가 운영하고 있다면, 사용자들이 로그인하거나 가입할때 목표로 하는 CAPTCHA 문제를 받아와서 사용자가 풀게하여 목표 사이트에 가입이나 스팸성 글을 올리는 방법입니다. 아무리 CAPTCHA를 어렵게 만들어도 relay 공격 방법은 막을수 없죠.
어떻게 계산했는지 모르겠지만, 전세계적으로 매일 대략 150,000 시간이 CAPTCHA를 푸는데 소비(낭비)된다고 합니다! 이렇게 허비되는 시간을 좀더 유용하게 사용하기 위한 프로젝트가 reCAPTCHA입니다. 역시 CMU 프로젝트이고, CAPTCHA 문제를 만들때 임의로 생성하는 것이 아니라, 오래된 문서에서 OCR로 판독이 안되는 부분을 문제로 내는겁니다. 하나의 문제만 내면 사용자가 정답을 입력했는지 알 방법이 없기 때문에, 두개의 CAPTCHA 문제를 내고, 사용자들의 입력 결과를 통계를 내서 오랜된 문서의 디지털화에 도움을 줍니다. 정말 반짝이는 아이디어네요. 아래는 reCAPTCHA의 예제입니다.
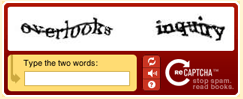
시간이 있으면 Tattertools 플러그인을 제작하면 좋을것 같네요. 찾아보니 없는거 같네요. 그리고 트랙백 받을때도 어떻게 활용할 방법이 없을까하는 생각도 드네요. 가끔 트래백으로 스팸성 댓글이 많이 달리거든요.