전에 CLucene CJK 분석기 리눅스용 소스를 공개하고 윈도우용도 공개하기로 했었는데, 계속 작업 안하고 있다가 마침 요청이 들어와서 정리했습니다.
압축파일에는 clucene-core-0.9.16a가 포함되어 있지 않으며, 압축을 풀고 아래와 같은 폴더 구조로 만들어주시면 됩니다. clucene 소스는 직접 받으셔야 합니다.
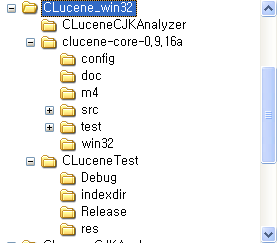
CLuceneTest 폴더에 프로젝트(dsw) 파일이 포함되어 있으며, Release에 실행파일을 포함했습니다.
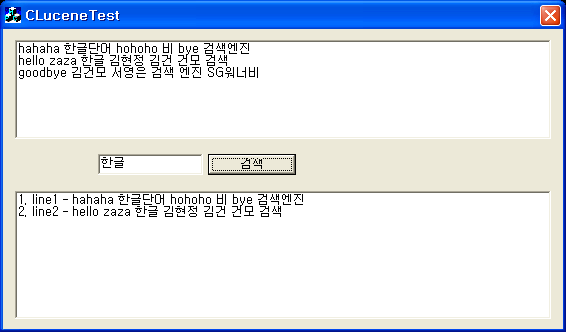
실행을 하면 아래와 같이 간단한 창이 뜨며, 위쪽 텍스트를 라인별로 인덱싱하며, 가운데 검색창에서 쿼리를 입력하고 검색하면 아래 검색 결과가 나타납니다. 검색 버튼을 누를때 위쪽 텍스트에 변경 사항이 있으면 인덱싱을 한후 검색이 됩니다.
윈도우즈에서 CLucene 예제를 만들면서 몇가지 문제점이 있었습니다.
Visual Studio에서 위저드 통해서 MFC 프로젝트 만들면 Preprocessor에서 _MBCS가 정의되어 있는데, 이게 있으면 CLucene이 잘 컴파일이 안됩니다. 두가지 해결방법을 찾긴 했는데 둘다 근본적인 해결책은 아닌거 같네요.
첫번째 방법은 프로젝트 전체에서 _MBCS 정의를 빼버리는 방법이고, 두번째 방법은 CLucene의 “StdHeader.h” 에서 #undef _MBCS 하는 방법입니다. 두번째 방법은 clucene 소스를 한줄 고쳐야하기 때문에 제가 올리는 샘플 프로젝트에서는 첫번째 방법을 사용했습니다.
컴파일 할때 주의 사항은 CLucene에 해당하는 C++ 소스는 “CLucene/StdHeader.h” 파일을 precompiled header로 사용하도록 해야합니다. UI 부분과 Lucene 부분을 분리하여서 UI 쪽에서 Lucene 함수에 직접 접근하지 않도록 했습니다.
컴파일중에 다음 경고가 뜨긴 하는데 실험해본결과 퍼포먼스에 큰 문제는 없었습니다. (제가 사용한 응용 프로그램 기준)
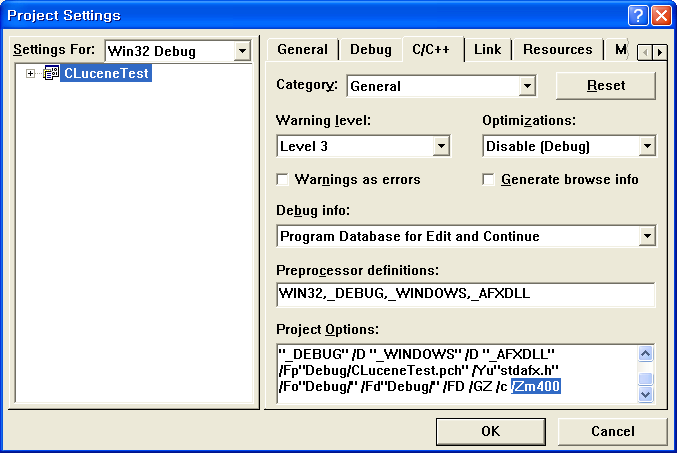
그리고 디버그로 컴파일할때 internal compiler 오류가 납니다.
아래처럼 프로젝트 C++ 옵션에서 맨 아래 수동으로 /Zm400 옵션을 추가해주면 문제가 해결됩니다.
소스입니다.