검색 기술은 제대로 배워본적이 없었는데, 서비스 운영하다보니 여러번 발목을 잡더군요. 서버에서 검색 기술이 필요한 부분도 있었고, 클라이언트에서도 필요했습니다.
클라이언트 단에서는 처음에는 인덱스 없이 직접 스트링 비교를 해서 검색하다가, 검색할 데이타가 늘면서 느려져서, 검색 인덱스를 메모리에 간단히 만들고 (stl map 이용), 사용하니 큰 문제없이 잘 동작하더군요. 근데 경우에 따라서 검색 인덱스가 아주 커지는 클라이언트 들이 생겨서 메모리에 전체 인덱스를 올리는것이 불가능한 경우가 생겼습니다. 그래서, 어쩔수 없이 파일 기반으로 map처럼 사용할수 있는 dbm 계열의 라이브러리를 사용하여 인덱스를 저장하여 사용하고 있습니다. 현재까지는 큰 문제없이 사용하고 있습니다. 하지만 검색 인덱스가 커지고 쿼리가 늘면 좀 버벅대더군요. 아무래도 인덱스 만드는거나 검색자체가 효율적으로 구현한것이 아니고, 저장하는 방법 또한 효율적으로 검색할수 있는 구조가 아니었던것 같네요.
서버 단에서는 디비에 있는 필드 검색이라 MySQL의 FullText 검색을 이용할 방법을 고민했었습니다. 요즘도 해결 안됐을거 같은데 FullText 검색은 한글을 지원하지 않죠. 그래서 고민하다가 생각한 방법이 한글을 영문으로 인코딩하여 필드하나 더 만들어서 박아넣는거였습니다. 일단 영문은 다 소문자로 변경해서 넣고, 한글은 대문자로 자~알 인코딩 해서 넣고, 디비 Insert,Update할때 인덱스 필드에 변환해서 넣고, 검색할때 한글 변환해서 fulltext search하고.. 이렇게 하니 잘 동작은 하더군요. 몇달간 서비스하면서 데이타가 몇기가 쌓이니, 점점 느려져만 가더군요. 이건 서비스 기획의 문제였지만, 운영하던 서비스는 거의 삭제의 개념이 없고 계속 누적되는 형태로 운영이 되었습니다. 그러니 문제가 될수 밖에 없었죠. 나중에는 검색을 새로 구현할 엄두가 나지 않아서 검색 자체를 빼고 P2P 검색으로 대체했습니다…
서버 단에서 다시 검색이 필요하여, MySQL fulltext보다는 좀더 좋은 방법을 찾으려고 했는데… 인덱싱하는 페이지들이 모두 html로 만들어져 있기 때문에, 웹기반 인덱싱 쪽으로 알아보았습니다. 외국에서 만든 많은 검색엔진들이 단어 단위로 인덱스를 만들기 때문에 한글 검색이 잘 안되는 경우가 많더군요. “검색엔진”이라는 단어가 인덱싱 되면 “검색”으로는 해당 문서가 검색이 안되는 엔진들이 많더군요. mnogosearch라는 검색엔진을 발견했는데, 한글 검색이 완벽하게 되더군요. 구현할 시간은 없고 일단 동작을 하다보니 그냥 사용하기로 하고 서비스 했습니다 –; 뭐 처음에는 사용자들이 검색 들어갔는지도 잘 몰랐기 때문에, 서비스 운영에 전혀 문제 없었습니다. 데이타가 쌓이고, 검색 많아지고 하면서 문제가 조금씩 생기더군요. 일단 서버 여러대에 분산 처리했습니다. 근데 문제는 몇몇 사용자가 검색을 집중적으로 해도 서비스가 상당히 불안해졌습니다. 서비스가 다운되거나 그런건 아니지만, 디비에 부하가 걸려서 응답속도가 느려지더군요. mnogosearch에 대한 최적화 방법 같은걸 찾아보고, 들어오는 쿼리들을 저장하고 벤치마킹을 해봤습니다. 처음 벤치마크 결과는 절망적이더군요. 일단 쿼리에 따라 검색시간에 큰 편차가 있었습니다. 내부적인 동작을 모르니, 최적화는 한계가 있을거 같다는 생각을 하고 mnogosearch를 대체할수 밖에 없다고 결론을 냈습니다.
로레벨(ㅎㅎ) 개발자이기 때문에 먼저 위키피디아에서 검색 알고리즘들을 찾아보고, 필요한 소스코드(주로C)를 수집하기 시작했습니다. 알고리즘 소스들을 연결하여 인덱싱하고 검색하는거 구현하는 거는 정말 쉬운일이 아닐거 같다는 생각이 금방 들더군요. 그래서 좀더 검색하다 찾은것이 루씬(Lucene)입니다.
루씬은 자바로 된 검색엔진입니다. 검색엔진이라는 용어 자체가 좀 애매한데, mnogosearch는 사용자를 위한 검색 엔진이라면, 루씬은 개발자용 검색 엔진입니다. mnogosearch는 인덱스할 url을 입력하고, 화면에 검색결과가 어떻게 표시될지만 설정해주면 바로 사용이 가능합니다. 루씬의 경우는 검색엔진 라이브러리입니다. 개발자가 직접 문서를 읽어들이는 코드, 인덱싱하고, 검색하는 코드를 직접 작성해야합니다. 또한 어느정도 기술에 대한 이해도가 있어야 좋은 성능을 낼수 있다고 하네요. 다행히 Lucene in Action이라는 책이 나와있어서 큰 도움이 되더군요. 번역판도 나온거 같더군요…
제가 자바를 선호하지 않고, 잘 동작한다면 클라이언트(win32)단에서도 사용하고 싶었기 때문에 C++로 포팅된 CLucene을 사용하기로 결정했습니다. CLucene이 자바 루씬에 비해서 버전이 낮긴하지만, 성능도 뛰어나고, 제가 C++이 더 익숙해서요…. win32 클라이언트는 종속성을 줄이기 위해서 static 링크되지 않는 외부라이브러리는 가능하면 안씁니다. ( 특히 .net 같은거는 절대 안씁니다. )
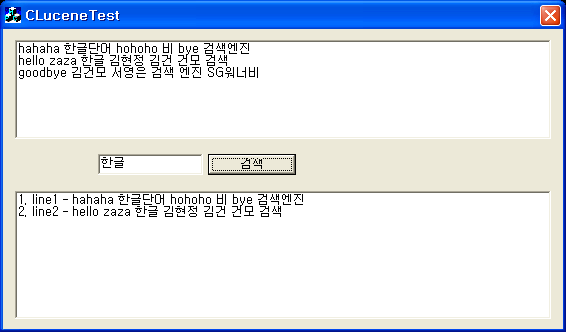
CLucene으로 현재 검색 서버를 개발 완료했으며, 클라이언트 단에도 실험적으로 돌려보고 있는데 성능은 아주 잘 나오고, 검색 시간 편차는 정말 적더군요. 서버단에서 벤치마크 결과 아주 만족스런 결과가 나왔습니다.
시간내서 CLucene으로 한글 검색 되도록 스탬필터로 개발한 소스를 공개하도록 하겠습니다. 한글스탬필터는 2글자씩 짜르는거 외에 별도 처리는 구현하지 않았습니다. 자바 루씬에는 이렇게 구현된 것이 들어있는지 모르겠는데, CLucene에서는 소스 찾아봐도 없더군요. 그리고 CLucene의 StandardAnalyzer로는 CJK 처리가 정상적으로 동작안하더군요. (win32, linux에서 모두)
소스 조만간 공개하겠습니다 ^^